


Dolly was cloned by Keith Campbell, Ian Wilmut and colleagues at the Roslin Institute, part of the University of Edinburgh, Scotland, and the biotechnology company PPL Therapeutics, based near Edinburgh.
She was born on 5 July 1996 and died from a progressive lung disease five months before her seventh birthday (the disease was not considered related to her being a clone) on 14 February 2003 [https://en.wikipedia.org/wiki/Dolly_(sheep)]
We are now ready to cover a more advanced concept -- cloning!
Our Datapipline API has the ability to easily clone a data stream into several copies. Common reasons for cloning the original data include keeping an unmodified copy or independently using the result of an expensive computation in different ways.
The component we are going to use for our new pipeline is the CloneDatasource() and it can be used like regular Datasources but with the exception, that it has more than a single output.
numberOfClones = 2
aCloneDatasource = CloneDatasource(numberOfClones)
So E.g. to set an output 1 to a data sink aDatasink we simply add the number of the output to the regular setOutput() method.
aCloneDatasource.setOutput(aDatasink,1)
And that is it!
Remember that if we split our pipeline into three branches, we also need three endpoints -- three Datasinks.
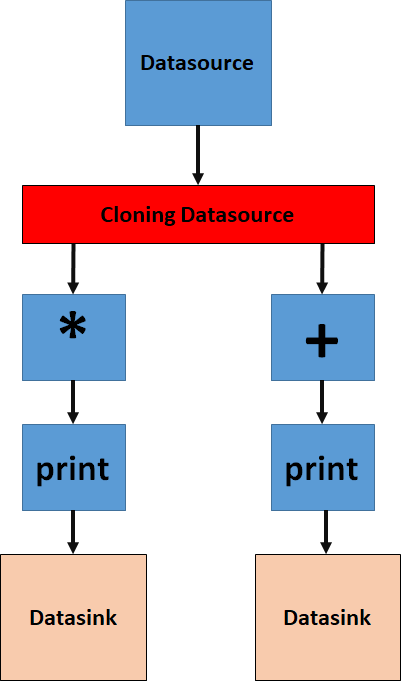
Like in our previous code, we are going to use a single Datasink and generate random numbers. We are then splitting the stream of data into two branches. Each branch contains the same data and independently processes the data. In the first branch, we will multiply the incoming data with some constant and in the second branch, we will add some constant. Both pipelines will print the value on the screen. To implement this, we modify and reuse our previous code. Fig7 shows what it will look like!
Before we begin, let's have a look again at the previously used DataProcessingPlugin.
class DataProcessingPlugin(pipeline.Plugin):
def __init__(self):
super().__init__()
def process(self):
super().process()
randomData = super().getDataframe().getData()
randomData *= 1000
super().getDataframe().setData(randomData)The slight issue with this implementation is that the constant is hardcoded into the pipeline code. But we can do better!
class MultiplicationPlugin(pipeline.Plugin):
def __init__(self, value = 1337):
super().__init__()
self.value = value
def setValue(self, value):
self.value = value
def getValue(self):
return self.value
def process(self):
super().process()
data = super().getDataframe().getData()
data *= self.getValue()
super().getDataframe().setData(data)
class AdditionPlugin(pipeline.Plugin):
def __init__(self, value = 1337):
super().__init__()
self.value = value
def setValue(self, value):
self.value = value
def getValue(self):
return self.value
def process(self):
super().process()
data = super().getDataframe().getData()
data += self.getValue()
super().getDataframe().setData(data)Both plugins let us define a fixed value that is added to or multiplied with the incoming data.
The addition we have to make to the previous example are rather simple.
Here is the new code:
import numpy as np
def example5():
numberOfClones = 2
fixedMultiplier = 10000
fixedOffset = 5
aDatasource = pipeline.Datasource()
aDataVisualizationPlugin0 = DataVisualizationPlugin()
aDataVisualizationPlugin1 = DataVisualizationPlugin()
aMultiplicationPlugin = MultiplicationPlugin()
aMultiplicationPlugin.setValue(fixedMultiplier)
anAdditionPlugin = AdditionPlugin()
anAdditionPlugin.setValue(fixedOffset)
aCloneDatasource = pipeline.CloneDatasource(numberOfClones)
aDatasink0 = pipeline.Datasink()
aDatasink1 = pipeline.Datasink()
aDatasource.setName("Our Datasource")
aDataVisualizationPlugin0.setName("Our DataVisualizationPlugin for multiplication")
aDataVisualizationPlugin1.setName("Our DataVisualizationPlugin for addition")
aMultiplicationPlugin.setName("Our aMultiplicationPlugin")
anAdditionPlugin.setName("Our anAdditionPlugin")
aDatasink0.setName("Our aDatasink for multiplication")
aDatasink1.setName("Our aDatasink for addition")
aDatasource.setOutput(aCloneDatasource)
aCloneDatasource.setOutput(aMultiplicationPlugin,0)
aCloneDatasource.setOutput(anAdditionPlugin,1)
aMultiplicationPlugin.setOutput(aDataVisualizationPlugin0)
anAdditionPlugin.setOutput(aDataVisualizationPlugin1)
aDataVisualizationPlugin0.setOutput(aDatasink0)
aDataVisualizationPlugin1.setOutput(aDatasink1)
for n in range(100):
aDataframe = pipeline.Dataframe()
aDataframe.setFrameNumber(n)
aDataframe.setData(np.random.random(1))
aDatasource.addDataframe(aDataframe)
aDatasource.run() The output looks like this:
...
Hello from: Our DataVisualizationPlugin for multiplication ID: 65446302
Frame number: 99
The data value is: [9722400.62683906]
Hello from: Our aDatasink for multiplication ID: 47053347
Frame number: 99
Hello from: Our anAdditionPlugin ID: 16880615
Frame number: 99
Hello from: Our DataVisualizationPlugin for addition ID: 91610042
Frame number: 99
The data value is: [5.97224006]
Hello from: Our aDatasink for addition ID: 33470743
Frame number: 99
Although the new code is admittedly larger, it is not really any harder to understand than the previous example.